
M3ViT
Published:
[NeurIPS’2022] M3ViT: Mixture-of-Experts Vision Transformer for Efficient Multi-task Learning with Model-Accelerator Co-design
Motivation
MoE允许多个任务集成在一个model中,同时也能让这些任务协同优化。现在MoE的问题其实很显然,就是训练时会有梯度冲突问题,推理时一般只需要其中一个任务,必须要有switch task支持。
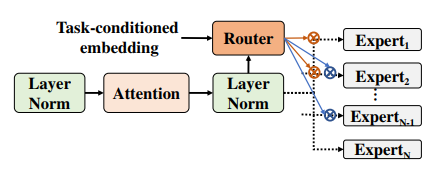
本文作者采用HW-SW协同优化,实现on-chip MTL,针对训练和推理任务。训练时会稀疏选择task进行,解耦任务间的参数空间,推理时只开启感兴趣的expert。硬件支持采用computation reordering scheme来零开销切换任务。
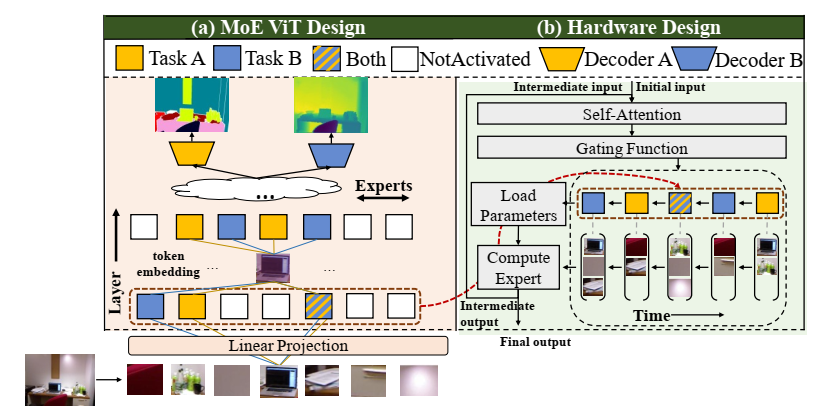
实验是通过把ViT的FFN换成hard-gated MoE(multi MLPs)完成,加入一个task-dependent gating network。
对于MoE accelerator来说,挑战在于expert的不停转换,这会带来很多loading上的负担。
Method
非常好理解,因为M3ViT不是采用spatial acc的结构,而是用layer-wise的计算,所以需要在runtime根据switch逐层的载入weight,这在switch切换到各个expert时引入了大量的data access。所以作者的想法是把token by token的计算转为expert by expert的计算,即在每个expert前放上一个queue,让每个expert轮流计算处理queue,新来的batch自动分到各个queue里,形成一个异步乱序计算流水线(这样乱序不会有正确性影响,因为batch间无依赖)。这样每个expert可以提前用double buffer预取(因为大家都是按顺序来的)。本质上还是时间换空间(latency很大)。
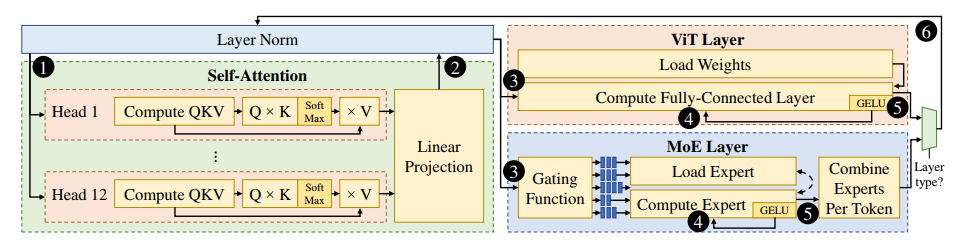
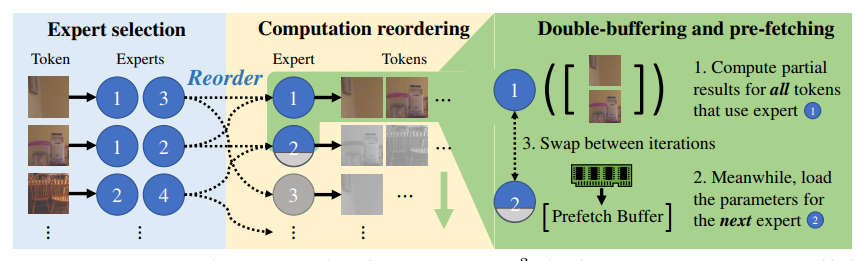
本文其余的内容主要集中在模型的训练上(而非硬件实现),可以之后在训练MoE时学习。
Comment
TBD