
DynaPlasia
Published:
title: [ISSCC’23] DynaPlasia: An eDRAM In-Memory-Computing-Based Reconfigurable Spatial Accelerator with Triple-Mode Cell
Motivation
存内计算CIM在减少数据移动和访存上提供一个能效优秀的解决方案,但是之前的工作很多都聚焦于Macro的能效优化,在端到端系统的表现上与理论相差比较大,所以一个系统层级上的架构优化是充分发挥存内计算能效优势的必经之路。
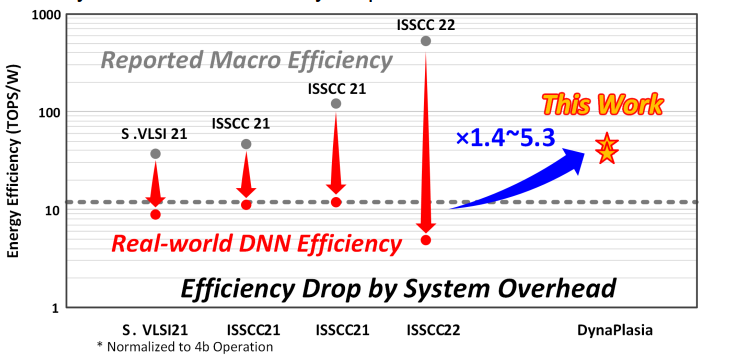
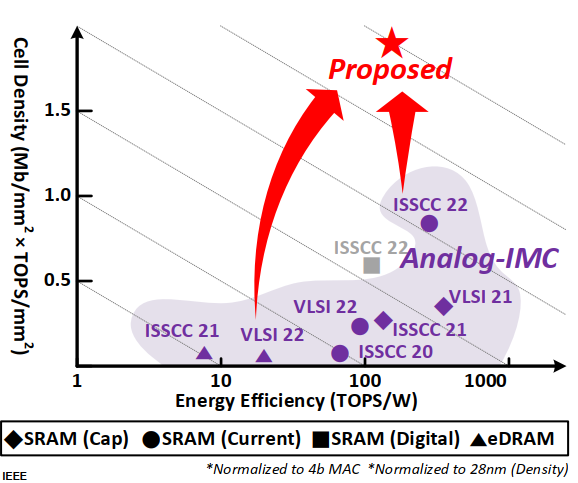
作者认为,目前在CIM系统集成上还有如下问题
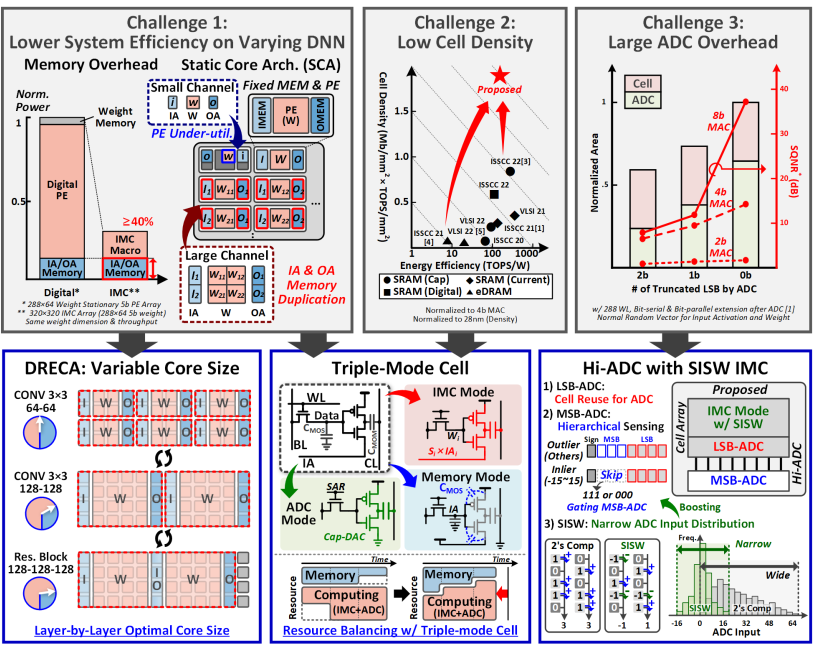
macro尺寸和配置固定带来的underutilization(有时太大),和单个计算core(也可以说是Macro集合)容不下单层,带来的同时在几个core内都有重复的IO数据问题(有时太小)
eDRAM-CIM中的大电容降低了存储密度,甚至比SRAM-CIM还低
正常情况下SRAM-CIM需要8-18管,相比eDRAM-CIM的2-3管来说就很多了,但是一般由于leakage的问题,电容会做的比较大,影响了密度
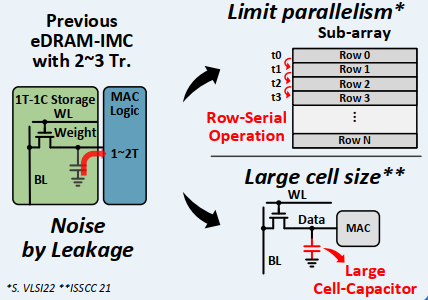
ADC面积太大,如果通过降低bit数减少面积又会带来量化噪音,所以不得不用高面积来挽救SQNR(signal-quantization noise ratio)
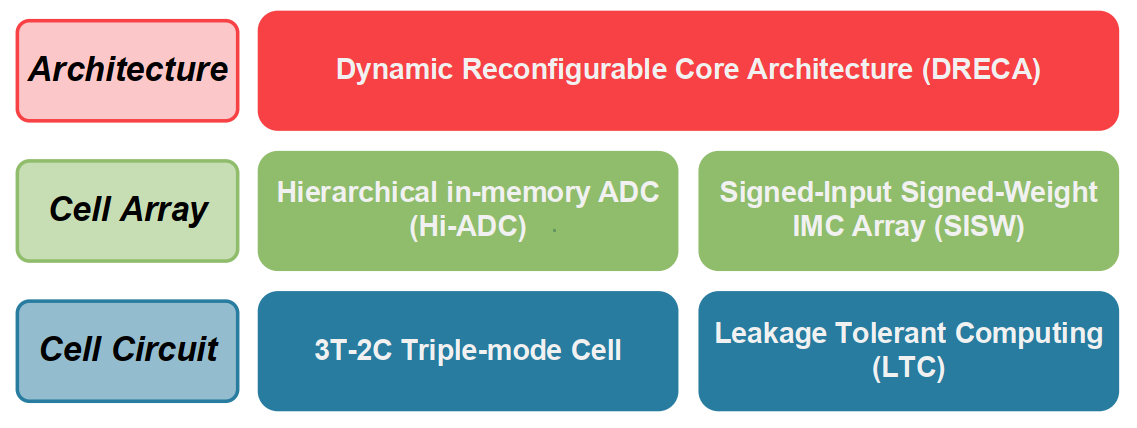
基于这些motivation,作者提出了DynaPlasia
- Dynamic Reconfigurable Core Architecture for higher system efficiency (most significant)
- Hierarchical in-memory ADC to reduce ADC overhead (circuit support for DRECA)
- Signed Input Signed Weight IMC Array for higher macro efficiency
Architecture
Overall
下图为芯片整体架构。Switchable Computing-Memory Macro(SCMM)通过3种链路(Systolic Link, Output Link, Control Link)形成reconfigurable dataflow network(RDN)。DMM(dedicated memery macro)是专门用来作input cache的。
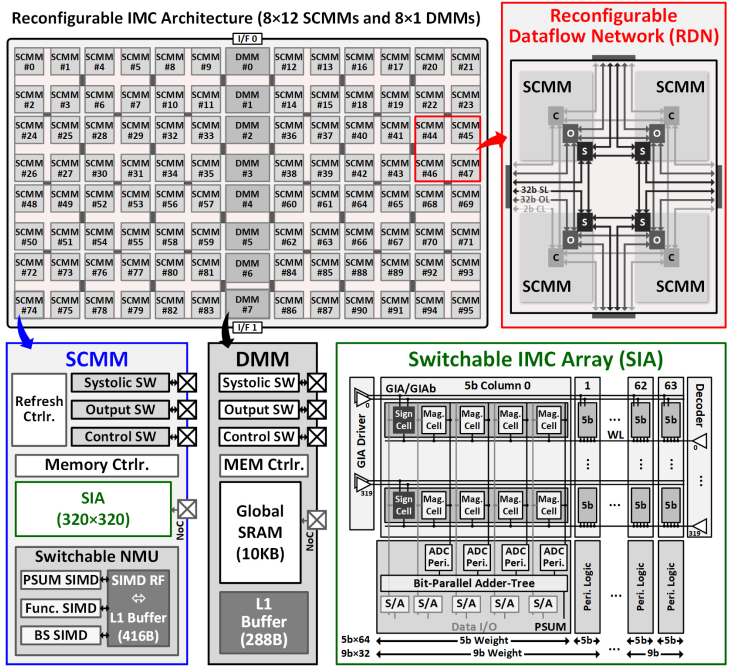
DRECA
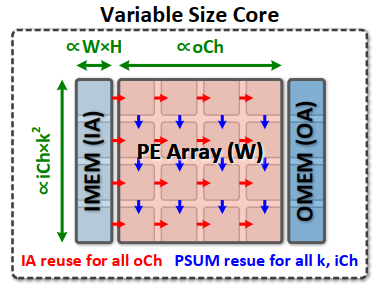
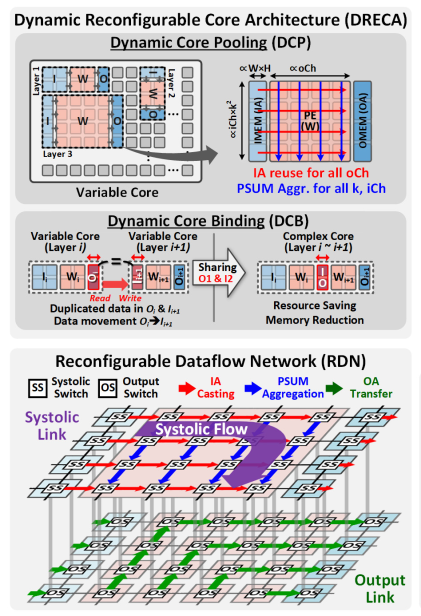
根据之前提出的问题,在系统层我们需要可配置的core来充分完成每一个layer,具体形式就是才用weight stationary的方式完成DCP和DCB,原理很简单看图就行。
这里其实还有一些系统层次上的问题
调度是由谁来做,是从cpu动态调度分配来吗,调度信息overhead多少
层与层之间是否有更好的连接优化(参考Tangram)
数据排布怎么做更好,在初始化的时候是否需要很大的overhead
IA和OA的占用块数是怎么选择的,他们需要存数据吗
CIM在未来系统中到底应该是处在现在的DRAM的位置上还是与其并列,如果是替代如何排布数据
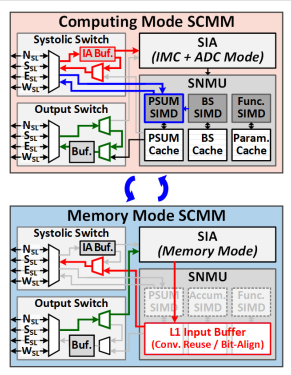
为了支持上面SCMM的可重构性,Macro本身支持两种模式:存储模式和计算模式。计算模式下Macro配置为脉动阵列的一个PE,完成流水作用。存储模式下只收集OA和发送IA,SIA就作为普通eDRAM cell。
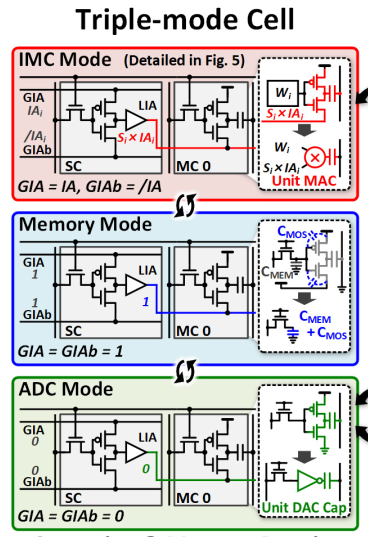
Triple-mode Cell
SIA为了支持上述对于存储单元和计算单元的转换,也必须配置成多种模式。本文一个cell可以变形成三种模式:IMC mode(计算), mem mode(只存储), ADC mode(对于IA/OA feeder),三种cell通过GIA(global IA)线上信号配置晶体管的状态做到。
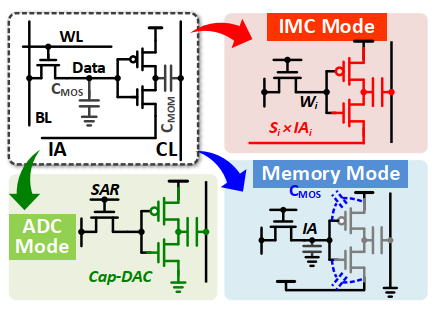
IMC模式是标准的乘法,这种一个反向器可以隔离模拟噪声,解决之前的leakage problem。
ADC模式是和下面的cell-based Hi-ADC配合的。
Mem模式就是普通DRAM cell。
这样一种动态配置可以充分提高cell的利用率,提高能效。
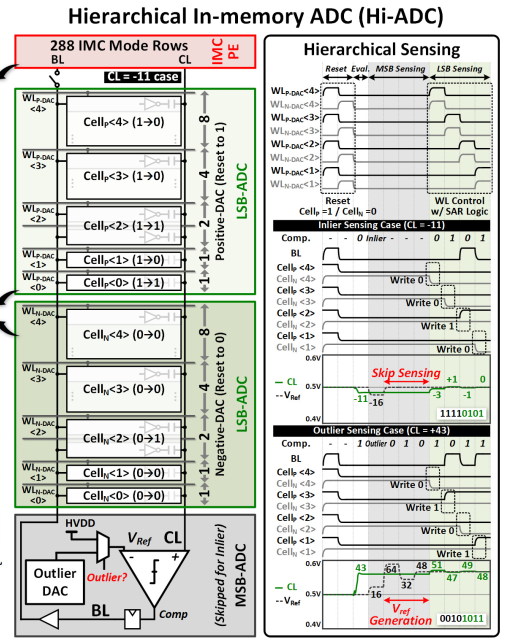
Hi-ADC
接下来详细讨论ADC mode的实现细节。这里采用了逐次逼近ADC作为基本原理,与以往不同的是,这里采用了两层的转换方案,将一部分的转换单元转为in-mem cell,减少了ADC面积。CL上信号会先进行是否为内点(inlier,-15:15)的判断,如果是则不需要启动外部的DAC,直接用0.5V做参考电源,如果不是才需要MSB sensing Vref generation,这一设计减少了能耗。最后的结果写在N/P cell中,分别代表正数和负数。
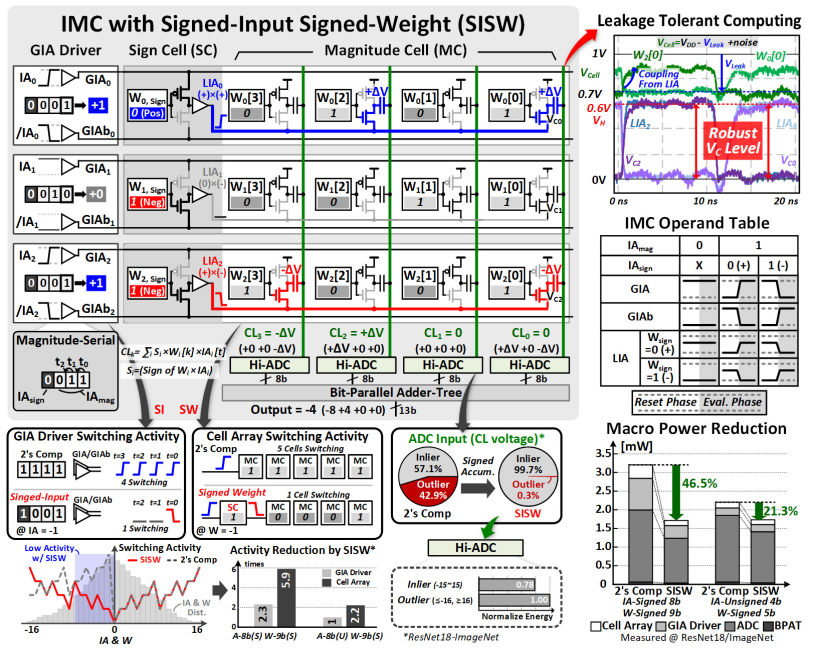
SISW
接下来详细讨论IMC mode的实现细节。
本文中作者采用signed magnitude存储数据而不是一般的补码,这是因为深度学习的数据排布一般类似于均值为0的正态分布,如果采用补码,那么在0附近的符号转变会消耗很多的翻转功耗,同时这也能减少CL上的分布均值和方差(也是减少翻转功耗和outlier数)。
具体点积计算可以看下图,一个col里是一个5bit权值,IA会先用符号计算得到LIA,LIA会作为mag计算中的可能结果方(虽然会带来很长的依赖链,有点类似异步电路)。IA是按bit serial输入计算的,所以会花几个cycle输入所有比特,下面的adder tree会完成生成部分和的所有累加和移位,SCMM里的SNMU会完成更高层次(几个完整数,而非比特运算)的累加,形成一个多级累加结构。
可以看到这里使用了robust digital signal完成了抗噪声的任务(多一层cap-ADC),同时也是多级信号的解耦,保证了信号的驱动能力和ADC的较好线性性。
Conclusion
本文针对eDRAM-CIM的三个痛点:ADC面积、泄露、固定core带来的利用率问题,做出了相应的解决,形成了系统级的解决方案(其实也只到chip level),并且有相应的微结构支持。
Comment
现在存算一体架构在论文中展现了很高的能效,但是在系统测试中却出现性能腰斩,这显然是因为系统适配能力造成的。我认为如果在系统上考虑,可以有下文几个方向
- intelligent controller
- scheduler
- data moving
其次,我观察到目前存算sys有采用一些accelerator架构来进行优化的趋势,那么这到底是一个accelerator,还是一个可以在未来代替DRAM的存储设备,异或是和DRAM并列?如果是后者,适配性和控制性如何?