
DOTA
Published:
Authors: Zheng Qu, Liu Liu, Fengbin Tu, Zhaodong Chen, Yufei Ding, and Yuan Xie
Intro
Transformer已经是深度学习领域最热门的模型之一,在各种场景应用(NLP,CV,etc.)中都占据SOTA地位。自注意力机制是Transformer的核心,具有极强的表现力,但是却有着一些固有的缺点,包括attention机制的平方计算复杂度(语句序列长度)和存储需求(大量矩阵)。
attention score matrix经过行softmax之后会形成一个状态转移矩阵,但是不是所有的边都是重要的,通过剪枝一些probability weak的边,可以减少计算。实验证明,某些应用中90%以上的边都可以移除。剪枝在一个encoder中只需要一次,剪枝的边id可以复用在LT,Multi-Head Attention Score和FFN的计算里。
相比于LT和FFN,self-attention的特点就是无参数的GEMM,这意味着无法通过访存上的trick来加速运算,必须要在runtime的query和key计算完毕才能开始计算,这导致attention score的计算随着序列长度增大逐渐成为主要瓶颈,而显然我们不可能在计算完原来的score matrix之后再剪枝,这样相当于仍然保持平方复杂度的高精度运算,没有充分体现剪枝的效果。
本文提出了一个加速transformer推理的加速器DOTA。
本文的novelty:
- 提出优化Transformer模型的访存和计算的DSA架构(RMMU,Lane,Token-parallel)
- 采用co-design的方式,提出一种优化了的轻量级Detector,用于检测和放弃注意力图上的弱连接。
Weak Attentions Detection
如何高效剪枝就成了关键。其他的文章包括angular distance approximation等方法虽然硬件友好但是效果不好。本文提出用low-rank transformation(不去计算原来的score matrix,计算一个小型的替代)和low-precision computation的方式来低精度计算 \(S=QK^T\) ,并在 \(S\) 上根据阈值来判断是否舍去。显然,直接随意定一个阈值来剪枝是不合理的,反而会降低模型性能。本文通过联合损失函数训练的方式来得到相应参数。
总的来说,DOTA的软件部分采用了一个小型的Detector模块,需要和原模型一起训练(训练时费点劲,但是推理时在LT这里节省了大量运算)。
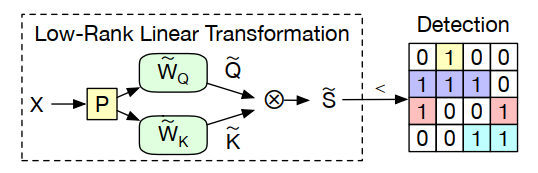
低秩分解即不采用主数据流上的权重 \(W_Q, W_V, W_K\) ,而是另辟一条路,采用P矩阵降秩,减少新的权重 \(\tilde{W}_Q, \tilde{W}_K\) 的大小(如上图),再采用低精度计算,通过一个可训练阈值来生成binary matrix。等到剪枝结果出来以后,原权重就没有这么复杂了,总的来说是大大降低了计算量。detector的损失函数可以设定为 \(L_{detector}=\frac{1}{n}\Vert QK^T-\tilde{Q}\tilde{K}^T\Vert^2_2\) ,联合损失函数可定为 \(L=L_{model}+\lambda L_{detector}\) 。
System Design
DOTA提供一个统一的架构加速所有部件,而非某些文章仅加速特定模块。为了提供一个scalable和unified的平台,DOTA采用了多种优化方法,包括para-lane,RMMU,token-parallel。
overall
Dota一次可以处理一个sequence,当然可以并行许多Dota。每一个Dota内分为很多个并行的lanes,每个lane分到一部分无依赖的输入矩阵(如下图的四色矩阵块),可以并行化,并且lane之间除了共享一个输入X以外没有数据交换,只需要最后accumulate即可。
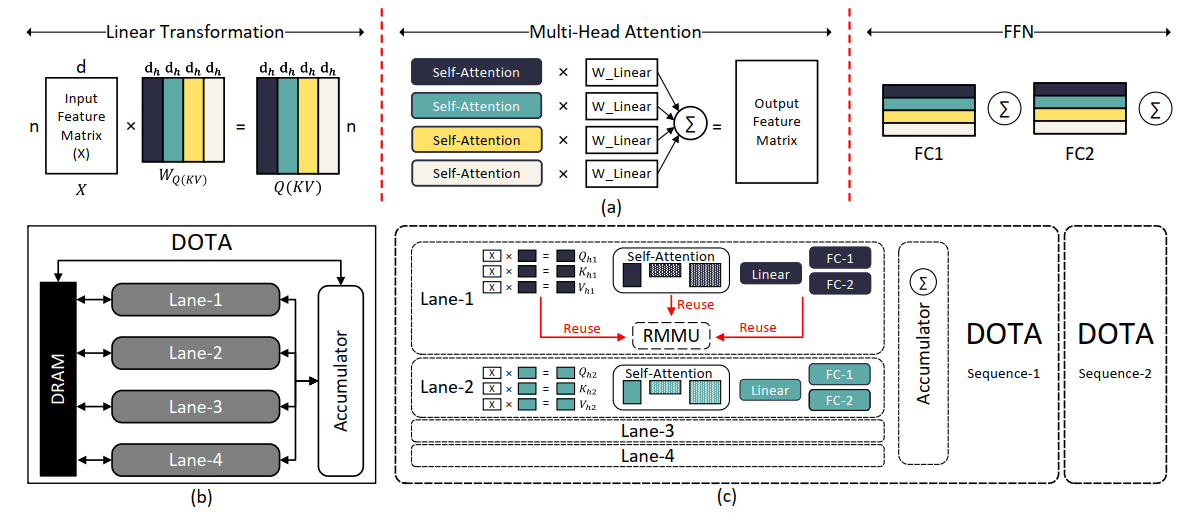
每一个lane的结构如下,RMMU是一个任务共享的计算部件,Detector是底层支持Detector模块的部件,MFU是综合了复杂计算单元的部件(包括FX16->FP16量化部件,之后在softmax前会使用,防止溢出)。
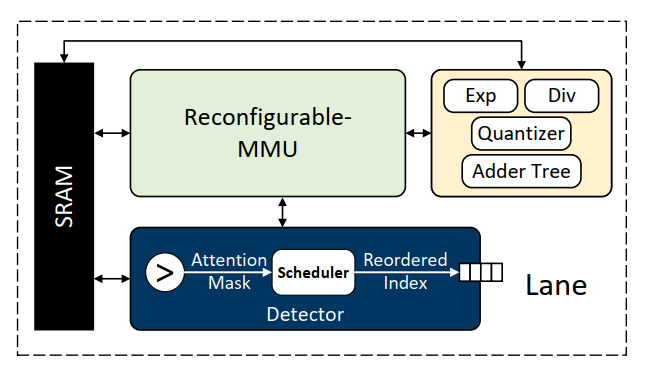
RMMU
在前面的算法层我们发现,RMMU需要同时支持高精度和低精度的运算,而两者的配比在整个模型的不同位置是不同的,因此我们希望高精度部件能和低精度部件可配置的互相转换。
转换的原理是这样的:
- FX16(16位定点数,可用来表示小数)乘法器本质上还是整型乘法,只是解释方式不同
- 高精度整型乘法器可以由很多低精度的乘法器组成
根据这两个基本原理,看到下图就能明白构造了
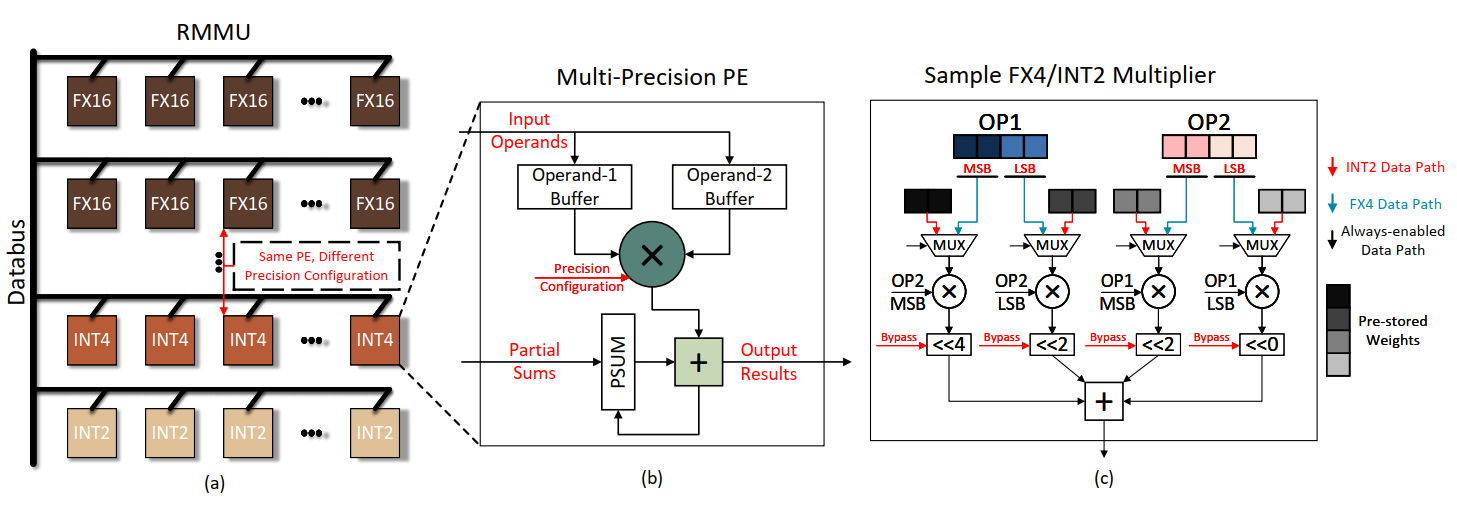
RMMU采用的是树形组织(稀疏矩阵不适合再用经典SA了),可以以行为单位配置精度(FX4和INT2共享位宽相同,导致吞吐量不同,文章还讨论了这个的解决方法),所以一个PE一次可以算4个INT2的乘加,或者两个FX4的乘。
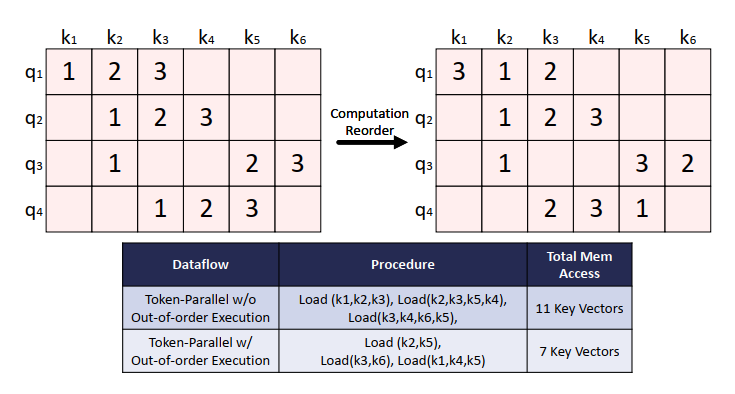
Token-parallel
在mask binary matrix生成后,score矩阵相乘时可以多行并行计算,这样可以共享列元素,但是要注意多行有效元素个数的不匹配,本文采用平衡的方式限制每行有效元素相同。
同时,scheduler可以根据某些原则重排非零元素的ID号(即重排计算顺序)。乱序的原则是更好利用locality,比如一列中有很多query都想要这个key,那么就可以把这些计算放在同一时刻进行,本文有相应的排序贪心算法来利用重用性。
Comment
在DOTA上,软硬件协同优化的好处体现了出来,在模型算法上提出的优化可以直接在硬件上找到直接的功能映射,大幅减少了调用成本,保证了理论性能和实际性能的一致性(在GPU上可能效果不好)。在这种思路下,其实很多看似在gpu上跑的效果不好的模型,在专用平台上就可以摇身一变成SOTA(adyna就是其中一例)。