
Eyeriss
Published:
Authors: Yu-Hsin Chen, Joel Emer, and Vivienne Sze
Reference1: Chen Y H, Krishna T, Emer J S, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE journal of solid-state circuits, 2016, 52(1): 127-138.
Reference2: Yu-Hsin Chen, Joel Emer, and Vivienne Sze. 2016. Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks. In Proceedings of the 43rd International Symposium on Computer Architecture (ISCA ‘16). IEEE Press, 367–379. https://doi.org/10.1109/ISCA.2016.40
Intro
本文提出了一种基于spatial PE阵列的数据流RS(row stationary),在支持并行性的同时减少数据移动开销(数据重用),提高能效并降低带宽压力。
为了控制除了数据流以外的外部变量,作者在相同的面积、处理并行度、工艺节点下评估能效,提出了一种分析框架,将不同的数据移动根据能耗分级,通过分析对不同级别数据移动的分析来量化比较不同数据流。
本文的novelty:
- 相较于之前只能针对某一种类数据移动优化的数据流,它尝试对所有数据移动类型同时优化,提出了RS数据流
- 提出一种量化分析框架,比较不同数据流
Dataflow Analyze
CONV的数据流总被写成如下的多层循环(假设已被padding):
$O[z][u][x][y]=B[u]+\sum\limits_{k=0}^{C-1}\sum\limits_{i=0}^{R-1}\sum\limits_{j=0}^{R-1}I[z][k][Ux+i][Uy+j]\times W[u][k][i][j]$
此外,z,u,x,y四变量还需要循环并行计算$NME^2$次。
其中$0\le z<N,0\le u<M,0\le x,y<E,E=(H-R+U)/U$,N为batch数,M为ofmap的channel数,E是ofmap的边长,H是ifmap的边长,R是kernel的边长,C是kernel的channel数(FC层可以看做一维CONV,所以也符合上式)。
所以,对CONV的数据流优化本质上就是将上述的循环尽可能的并行化(无论是空间还是时间),并增加数据复用。
Existing Dataflow
Weight Stationary (WS)
在PE的RF里固定存上weight pixel,使之重复利用$NE^2$次。$RR$ 的kernel被map到 $RR$ 的PE array上,每个ifmap pixel广播到每个阵列,psum在PE间spatial accumulated。
这种方法挖掘了weight reuse,ifmap reuse,convolutional reuse。(这种方法缺点可能在于ofmap都算了,但是都没算完,psum整出来一堆需要缓存)
Output Stationary (OS)
在PE的RF里固定存上psum,同一时间只取4D ofmap的一个子区域计算,直到算完为止(这就是集中力量办大事,不至于psum过多)。
可分为multi/single ofmap channel,multi/single ofmap pixel:
- SOC-MOP 挖掘了邻近pixel的convolutional reuse
- MOC-MOP 挖掘了convolutional reuse和ifmap reuse
- MOC-SOP 挖掘了ifmap reuse
No Local Reuse (NLR)
将循环完全空间展开,PE array被分为各个区,同时计算不同kernel channel的结果,最后在空间上直接相加,免去了RF的需求,所以global buffer可以做大一些。(ifmap reuse被丢弃)
Proposed Dataflow
因此,作者分析并提出了要解决的两点问题:
- data handling(data reuse)
- adaptive processing(programmable)
其中第一点有实现难度,因为maximum input data reuse不能与immediate partial sum reduction同时实现(从上面可以看出,简单dataflow很难在相同资源限制下,高度reuse的同时还减少psum数量),作者认为需要设计dataflow同时完成二者。
From 1D Conv to Two-Step Primitive
作者提出使将高维的卷积运算分解成很多个1D Conv原语,每个原语计算one row of filter weights and one row of ifmap pixels, and generates one row of psums ,psum会暂存并在后面逐步加和。
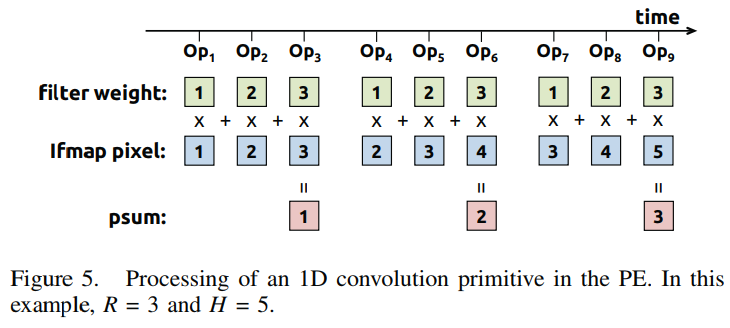
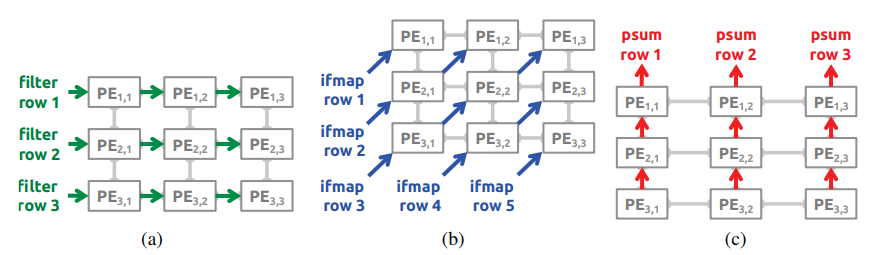
每个原语映射到一个PE,所以是Row Stationary,但是仍需要优化,因为显然同时映射所有原语是不可能的。
所以,作者采用了两步法
logical mapping
首先,将原语映射到无限数量的逻辑PE上,并将具有数据重用关系的PE组合成一个logical PE set,set内的kernel,ifmap,psum通过NoC共用。对于Conv运算共需要$NMC$个set。
physical mapping
其次,根据array和RF的大小,将若干数量的logical set映射到相同的physical set上。作者还解释了为什么在set粒度上fold而不是其他粒度:保持intra-set的结构,并且$NMC$个set之间有很强的reuse,所以会Folding multiple logical PEs from the same position of different sets onto a single physical PE。这个过程叫做processing pass。
根据Global buffer的大小 ,可以继续折叠 processing pass。
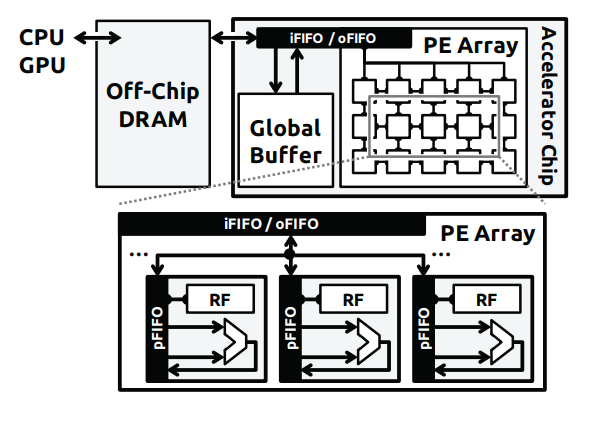
Architecture
为了完成不同层级的数据重用,Eyeriss采用四级storage hier: DRAM,global buffer,array (inter-PE communication),RF,分别挖掘不同的重用性。
Comment
总结来说,Eyeriss主要是在细粒度分解(row)和数据重用优化的交叉数据流上的创新,有效解决了intro里提出的问题。
同时,Eyeriss处理器强调着能效优先的规则,这点与学术派的架构设计有着明显不同侧重(更加注重绝对值)。ISCA版主要是采用分析模型来优化配置,达到最佳能效。JSCC版则是用流片数据来说明。
eyeriss的jscc版值得后续深入研究,对于内部机制有着更加详细的描述,之后可以查阅源码复现。