
Tangram
Published:
Authors: Mingyu Gao, Xuan Yang, Jing Pu, Mark Horowitz, and Christos Kozyrakis
Intro
基于tile的架构是面对日益复杂且庞大的DNN的提高加速器capabilities和efficiency的重要方式,因为它使网络不仅放得下,还能充分挖掘无依赖数据之间的并行性。它支持两大粗粒度并行:层内并行和层间流水,然而目前细粒度并行上仍有挖掘空间。
本文提出三个novelty:
- 层内buffer sharing: 将不同tile的分布buffer联合成shared buffer,减少冗余和相同数据的多次存取
- 层间alternate layer loop ordering:更加细粒度地前递数据,减少buffer需求量和流水线延时
- 复杂DAG的流水计算单元的拓扑分配,最小化off-chip mem读取
Background
本文采用eyeriss(MIT的深度学习处理器)作为baseline,在不改变baseline构成的前提下应用三种优化方法。eyeriss的架构是tile加速器的典型,整体为两级tile分割。一个engine由2d spatial pe array组成,公用一个buffer,挖掘细粒度并行。
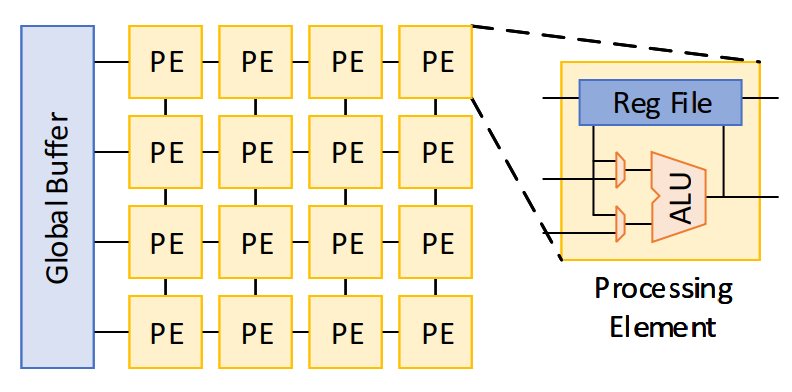
上层chip是由2d spatial engine array组成,NOC负责连接和与off-chip mem的互联。
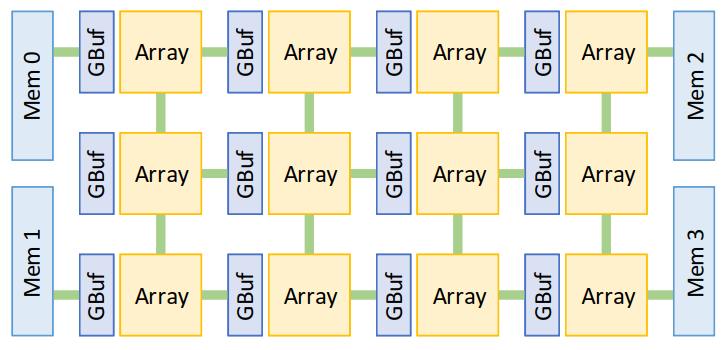
从数据流的角度来看,对于CONV运算,一个加速器的效果取决于nested loop如何被有效展开、变换(交换)、调度(空间分配)。因为on-chip和off-chip之间的交换次数会直接影响性能,所以需要最大化数据重用。
为什么不直接增大每个engine里的PE数呢?这会有四点问题:
- 较小的层不能充分利用,并且一个engine里有多个CONV运算会干扰。
- 启动延时和耗能增大
- PE与Gbuf之间的最大距离成为瓶颈
- 不能支持层间有效流水(连接方式僵硬)
Proposed Dataflow
Buffer sharing
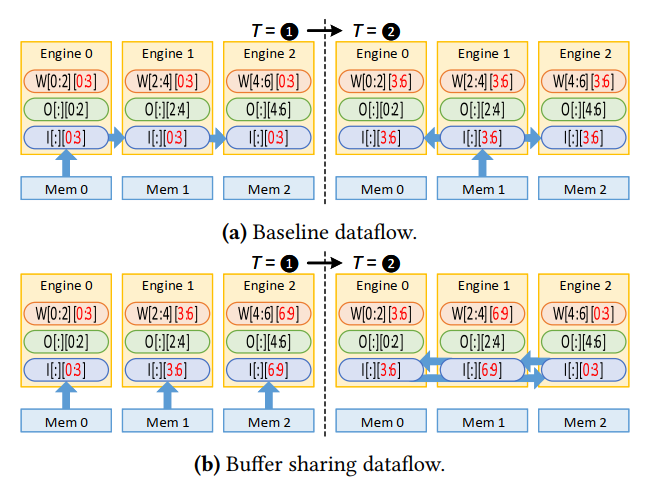
图a是一般的OS数据流,可以看到这种广播式的数据移动使得每个buffer里都存放上了相同的ifmap,相当于一份ifmap被同时存放了三份。这在数据移动时间上就出现了浪费(只取一份可以多取几种),而且过多的冗余占据了大量有效空间,影响了重用机会和buffer的可用大小。
因此,本文提出了图b的方案,首先skew the computation order across the engines,每个engine取不同的subset,由加法的交换性知这是可以的。随后rotate各自的数据直到都计算一遍。
同理,还可以hybrid rotation,保证相同数据只有一份。这种性质很像一个完整的具有NUCA的大buffer。
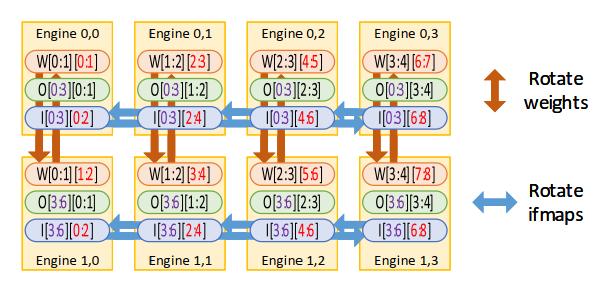
Alternate layer loop ordering
接下来是对层间pipeline的优化,虽然层间流水对整体性能和利用率提高很多,但是却需要暂存大量中间结果,并且长流水会导致大延迟。
有一个很直观的想法是把中间结果分解成subset(batch级),每个上层subset计算以后就可以开始计算下一层。但是会有两个问题,一个是推理时batch数很小,这种粗粒度的分解很难进行,一个是分解会影响weight重用。
所以我们需要更加细粒度的分解。下图直观的展示了这种方法(comment:划分个数不能太大,因为跨subset的计算占比会增大,后期补充计算会比较耗时)
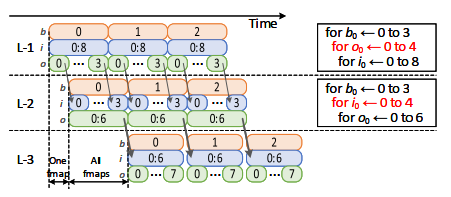
这样我们成功的减小了流水线的长度,并且可以forward and buffer the exchanged fmaps in a finer granularity,减小中间buffer需求。
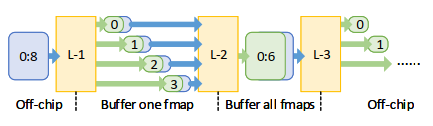
但是从上图可以看出,由于conv计算只能同时分解ifmap或ofmap,所以只能两两采用ALLO。(comment: 感觉还是要取$t_b$次weight,好像甚至会更多,除非片上缓存很大可以一直保存所有weight。我没有很理解这个reason)
Region Mapping for Complex DAG
之前的设计对于层的计算资源分配采用简单的1D分割(分割列数),但是这种策略对非线性网络不成立。所以作者引入2D zig-zag allocation strategy,在线性分割空间不够时可以折叠进下一行,更细粒度地灵活地分配空间。
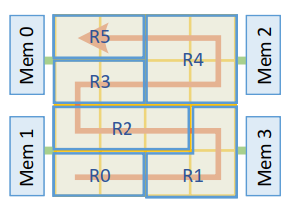
方法论主要有两步:
- segment selection
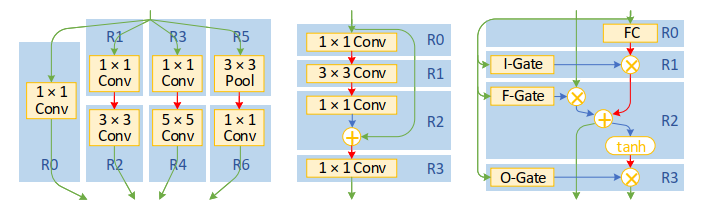
首先是选择哪些层组成一个pipeline segment,依据是是否有相同的数据依赖,目的就是减少相同数据的多次存取。比如下图的googlenet,可以将R0,R1,R3,R5组合成一个segment,而对于像LSTM一个segment很大,不能全部放在片上的情况,可以允许有一个层在其他segment。
- region mapping
接下来将一个segment里的层进行空间分配。分配原则是不允许一个region有对领居region的多个依赖,防止时序依赖导致的停顿。
Training
Scaledeep里提出,反向传播训练的计算也可以看做一个新的具有不同维度的Conv层,所以之前的优化数据流都可以继续采用。
Experiment
TBD
Comment
Tangram对数据流优化提出了新的novelty,有效的解决了细粒度和全网络映射上的inefficiency。
在最后的Related Work中,可以看到一些别的研究方向:
低精度小控制计算
稀疏性挖掘(很有价值,很大影响细粒度数据流)
3Dmem
RRAM
….