
Networks of Chiplets
Published:
title: A_Scalable_Methodology_for_Designing_Efficient_Interconnection_Network_of_Chiplets
authors: Yinxiao Feng, Dong Xiang, and Kaisheng Ma
Motivation
chiplet技术是目前工业界和学术界都很看重的研究方向,一方面chiplet能通过芯粒重用减小成本并降低开发迭代时间,另一方面在可拓展性、良率、并行性性能挖掘方面都有很好的特性。
当然chiplets之间的互联结构会成为很大的一个性能因素,目前的互联结构大多是基于2D-mesh的(很少会有nD-mesh, hypercube, dragonfly),这是基于实现的考虑。但是现阶段的工作都或多或少没有很好的在互联上解决chiplets结构特有的问题,还保留比较原始的2D-mesh-NoC结构,不会采用长连线或者是低网络直径的拓扑结构。这在片上是没有问题的,因为scale还比较小,但是在chiplet级别(甚至是wafer-scale)会导致一些性能和可拓展性上的缺陷(比较容易想到的是网络两端的通信性能,直径是$O(\sqrt{N})$)。
作者总结了两个challenge:
- 不同scale下的设计方法是不同的,tradeoff会有区别
- 片上routing策略不能直接拿来用,因为直接将几个NoC连起来会有潜在的死锁和拥塞问题,同时像刚才讨论的,简单的维序优先策略在大量的核数面前是一个很大瓶颈。
目前也有一些其他工作提出了自己的解决方式,比如说turn restriction(需要修改硬件并且会有load imbalance问题), remote control(需要大量buffer),adapt-noc(目前适应性还很有限,并且只能支持flat topo)。
innovation:
a method to scale high-radix 2D-mesh network
a scalable deadlock-free adaptive routing algorithm for most common topologies
a safe/unsafe flow control
a network interleaving method
Background
Chiplet Arch
作者介绍了一些chiplet方向发展的情况,目前chiplet靠着packaging tech和high-speed high-density wirelines(serdes,2.5D)获得了很好的拓展性和多样性,甚至可以有一些超越之前平面flat结构的方式互联(包括多维互联和环形拓扑),这在之前的单die上是很难做到的。现有的一些设计没有利用到这一多样性,仍采用flat设计。
同时作者也提到了chiplet的拓展性,chiplet可以适用于各种场景下的工作负载,无论是边缘端还是服务器端,这可以使得芯粒可以重用在各个场景下,形成开发成本的巨大降低。
Network on Chip
这一部分介绍了基础的片上网络原理。在并行计算中,尤其是超算中,互联架构是非常重要一部分。下面依次讨论network三要素:topo、routing、flow control
- 拓扑结构
正如上面所说,一个拓扑结构的好坏会决定packet的hop count和latency,网络直径则会影响最大值。对于大规模互联,我们倾向于选择直径比较大的互联方式(hypercube)。下图列出了一些常用的静态互联网络。动态互联网络则包括crossbar、bus等可编程改变拓扑的方式。
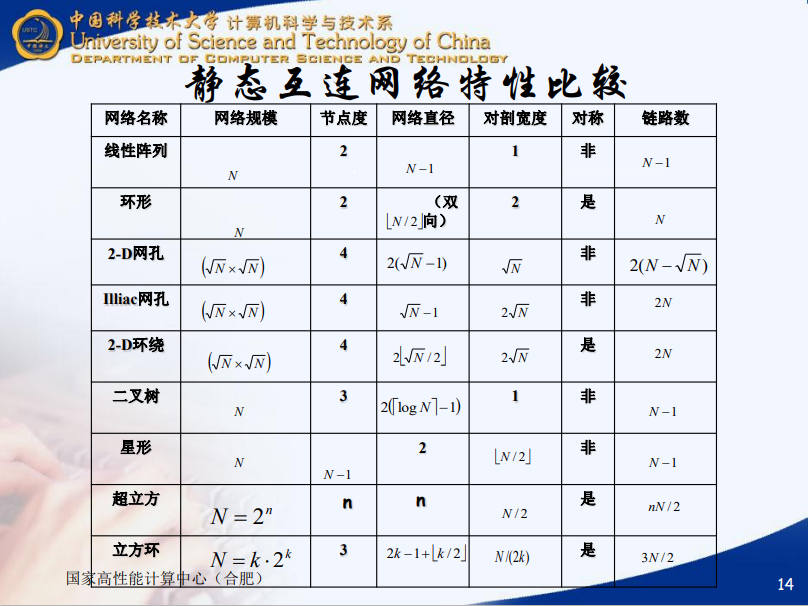
还有一些特殊性质比如超立方网可以完美嵌入2-D环绕网,这证明二者的routing本质上是相似的。
- 路由算法
为了防止死锁,可以采用virtual channel的方式,将物理通道分时复用以隔离对channel资源的依赖性。但是VC数一般不采用太多,否则会有太多的overhead。
关于死锁的解决,有一个充分条件可以做到

这个定理有一些定义我没有很清楚,但是可以看出一点,我们只要有一个baseline channel network routing满足deadlock-free条件,那么我们就能在这个算法的基础上引入其他efficient的结构来提升性能,毕竟有baseline兜底(作者用escape channel逃生通道形容),如果死锁了也能有方案解决。
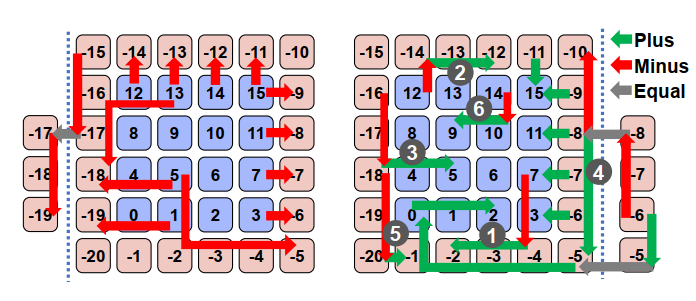
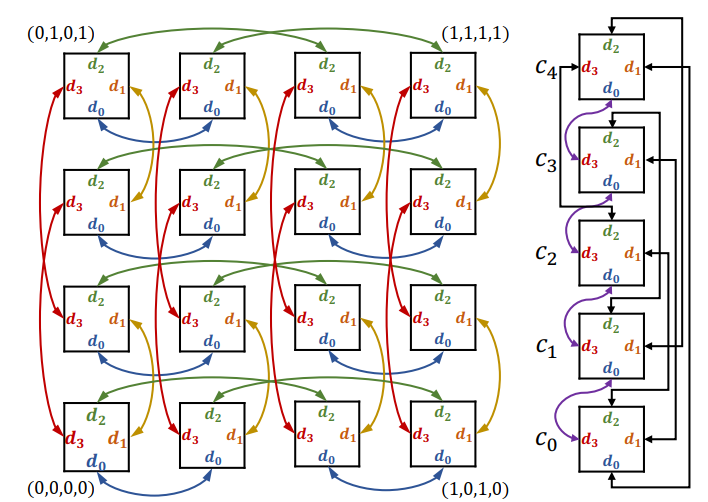
关于路由算法,作者采用了Minus-first routing(MFR)。这种算法是将每个节点编一个号,从小号到大号的link为正,反过来为负,命令正不能转为负link,这样便移除了dependency cycle,也即负号优先。但是这种编号系统拓展性很差,一旦改变scale和topo就需要重编。后面会更深讨论。
下图给出了在规则下所有可能的6种路径,根据link type和起终点的性质分类。
Interleaving
多体交叉访问在存储访问中是很重要的一环,因为它的程度会直接影响最大带宽。在chiplet间我们也是采用multi-channel的方法,但是现阶段的设计一个message只能走一个channel,浪费了很多可用带宽,本文会做出优化。
Interconnection of Chiplets
作者说了很多,我总结为以下方法:
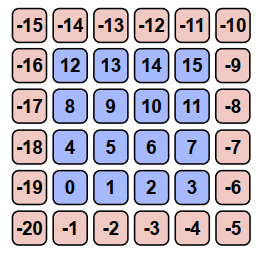
- each node has a label for routing
label-based routing是比较常用的方法,比如下图就是一个例子,采用了自然顺序标号内部core,而有序的negative label ring作为interface nodes标号方法。
- interface grouping
为了采用multi-channel,作者把几个相邻的physical link在软件上看做一个link group,这样一个chiplet node可以抽象成任意度,既能保持高radix的。当然为了利用好multi-channel,还需要interleave技术来辅助。
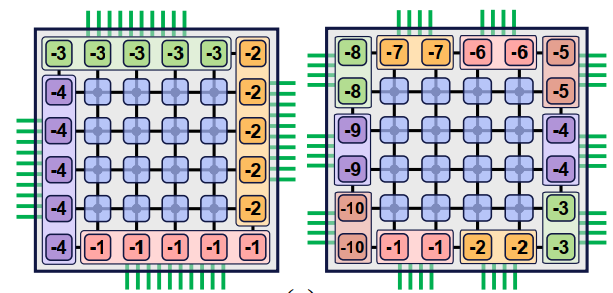
- interconnection method
虽然我们把interface nodes划分成了几个组,但是不同组毕竟在空间上是不等价的,所以不同chiplet间的连接会有比较大的影响。作者观察到两点:一是如果我们用相同的label互联,那么MFR可以拓展到多chiplet;二是在intermediate chiplet上的出入口越近延迟越低(很显然)。根据这两点,作者针对不同的拓扑给出了相应的结构。
hypercube(left), fully-connected(right):
超立方为了保证label consistency,只将相同序号的组连接起来,比如说d1只连接dim=1:(0,1)的两个chiplet。dragonfly也采用了一种可以适用于MFR的连接方案(给了文献但没有具体介绍)。
我们可以发现这么一个情况,上图如果有packet从-4进来,那么这个chiplet一定是他的目的地址,这说明一个包是unsafe的可能性存在。
nD-mesh:
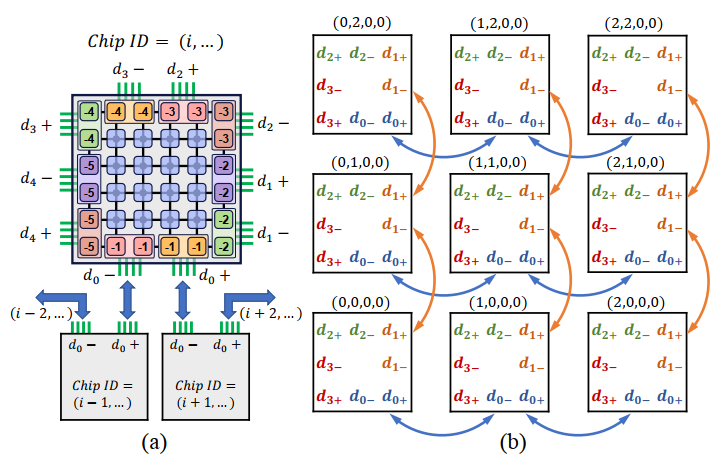
这里是分成了2n个group,要求只能adjacent label的+与-相连。hypercube是nD-mesh的特例,限制每个维度只有2个元素。
Routing Algorithm
Minus-first routing
Minus-first routing(MFR)是一种优先走-号路径的算法,只能从负号link转向正号。定义如果一个packet所在位置具有一个到达目的地的minus-first path,则它是safe的,否则unsafe(无法按规则正常到达目的地)。显然,这不是一种贪心算法。
整个routing的方案可以总结为下表:

其中最复杂的就是从一个chiplet的core到另一个chiplet的core,需要经过以下步骤:
- 先走only minus path到一个IF
- 沿着IF ring负方向到自己的目标出口,然后从link出去
- 到达另一个chiplet,沿着IF ring负方向,直到相邻的core label是比目标label小的才进入core(保证了不违背plus-second)
- 后面走only plus path到达目的地
可以发现,算法的具体实现还要注意很多,比如很多的packet会尝试从-19和-1进入core,因为相邻的为0节点,必然存在路径到达目的地。所以还需要其他的流控制和VC来调节拥塞程度。
Deadlock Issues of Equal Channels
注意到作者对同一个group全部标记了相同的label,所以equal channel会出现在两个地方:intra-group, inter-chiplet,而这会在nD-mesh的某些时候造成死锁(hypercube和dragonfly 没有这个问题),比如在下图中的相同维度的三个相邻chiplet出现了equal-equal 的竞争依赖环。因为这些group全是label等价的,所以可以以任意的合法方式routing,这导致了冲突,存在一种不违法的情况使得四个packet在其中互相依赖对方的link。虽然这种情况可以用其他方式(比如cost function)规避,但我们最好能根除这个问题。
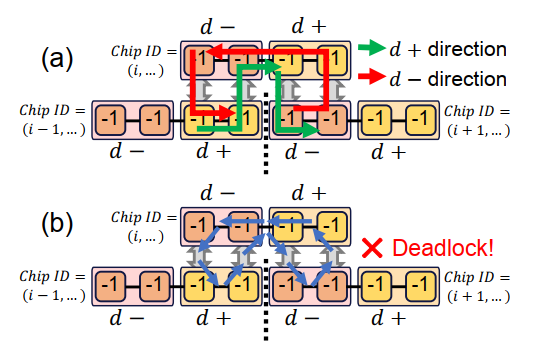
一种直接的办法就是不要把同一个group中每个IF标为相同的label,但是失去这种等价性无疑增加了算法复杂性,并且这会无法采用group的概念,从而在chiplet-level上不能用单link来抽象,也就不能采用正常维序路由的方案。
因此,作者修改了MFR的规则以避免这一问题。

简单来说,它使得环路不可能出现,如果有从+link进入equal group的packet,则分流到其他sub-network上,保证原来网络的资源不被占有。同时条件3也限制了equal label内的流动。
具体实现的话,只要在IF节点上增加一个VC即可将d+和d-的包分开,保证没有资源争抢问题,而且这种实现只需要在IF上改变就行,不需要改动cores。
Flow Control
flow control的具体实现是尝试利用好非baseline VC的其他VC,以使得MFR有时候非最短路径的问题得到缓解,而且MFR path有时候是很难找的,不能完全依赖baseline。
flow control算法如下图所示。简单来说,就是为了把VC资源全部利用上,同时限制目前没有移动机会的包在本地,而不是堵住相邻节点。

我们已经知道safe packet不可能形成死锁。那么只有可能在unsafe packet形成依赖环,但是可以发现这要求该unsafe packet在相邻节点也是unsafe的,即会存在相邻的几个node里的packet始终没有到达各自目的地的MFR path(可以认为这几个节点被孤立了,label必须非常特殊才能达到),作者claim这种情况基本无法发生。
目前的flow control放松了这一限制,带来了很多便利,而且允许最短路径方法前进(只要有位置+前面是确实是通的,我感觉这是限制死锁情况的逻辑),即使两点没有MFR path也有可能通信。
Example: hypercube
算法贴出来,对照之前的函数实现可以明白原理

hypercube没有死锁问题。
Network Interleaving
出发点很显然,就是把packets均分到一个group的各个IF上,实现方式就是改一改Core2IF函数的target IF。修改方式分粗粒度和细粒度(按照修改周期分,一个packet改一次就是细粒度,几个packet改一次就是粗粒度)。
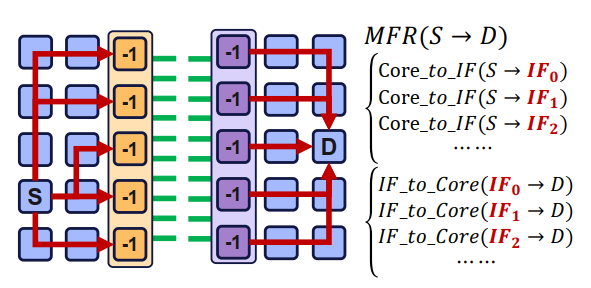
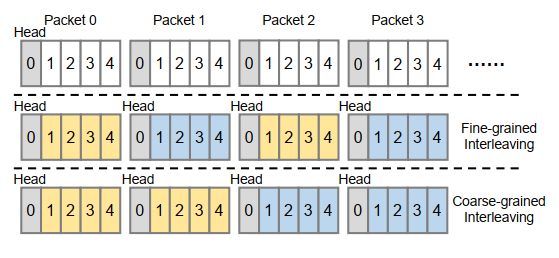
优缺点也很明显,粗粒度的在轻载下基本没有优化,但是可以减少能耗并且实现简单;细粒度的效果更好更平均,但是能耗大且电路复杂(需要反复切换逻辑)。
interleaving带来的乱序问题本文没有解决,不过可以参考TCP/IP协议的方式在端上处理。
Evaluation & Conclusion
作者写了一个C++模拟器,并且以Duato’s protocol based adaptive negative-first routing (NFR) on 2D-mesh为baseline,本质上就是不采用本文的core/IF-label method,而是直接当做一体网络(显然baseline没有对chiplet做特定优化),展现本文的方法效果。
这里介绍一下流量矩阵traffic matrix的概念,简单来说就是把N*N-1个节点对的各自独立流量形成的列向量映射到L个实际link的流量上,显然一个entry代表一个节点对对这个link的流量贡献。
- task1: 作者在四个pattern上比较:uniform(random), uniform-hotspot(10% active), permutation(4 specific patterns),topo选择2D-mesh(baseline), 3D-mesh, hypercube
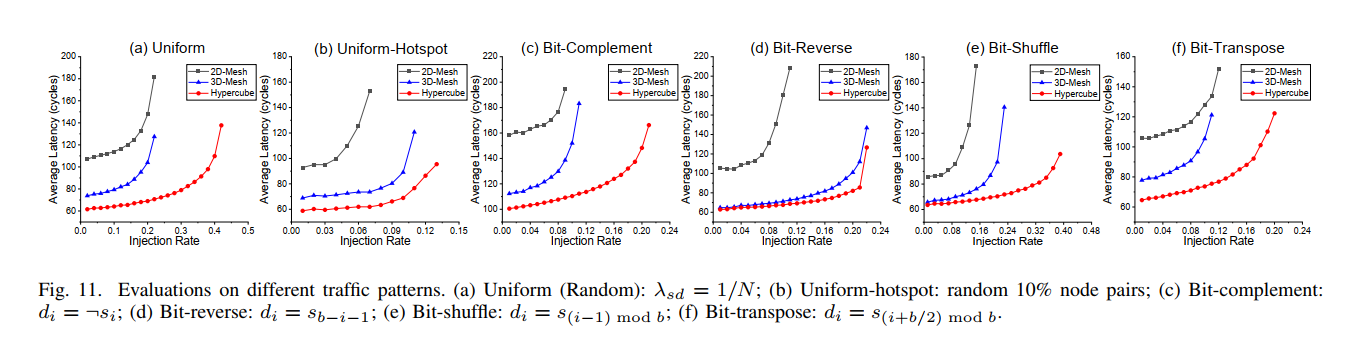
可以看到无论是饱和注入率还是延时都是优于baseline的,具有很高的适应性。
- task2: scalability
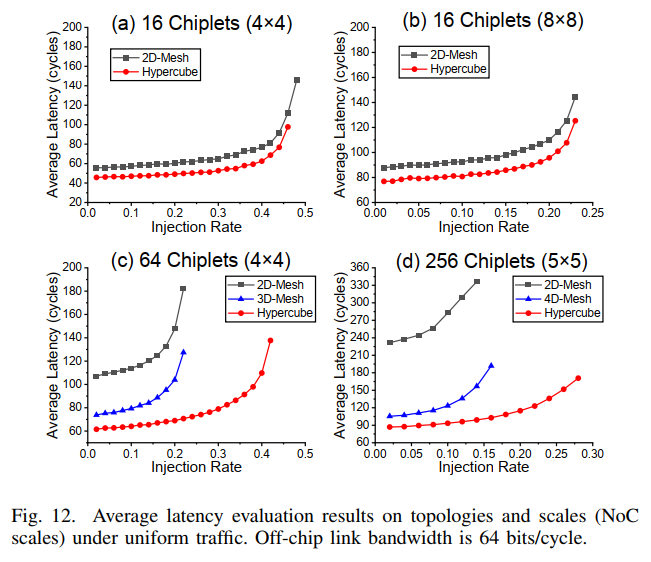
可以发现,增大NoC大小,会使得intra-chiplet的占比增加,从而增大延时并减小饱和度。增大chiplets数目,方法效果逐渐拉开优势,并且scale对其的影响很小。
- task3:energy
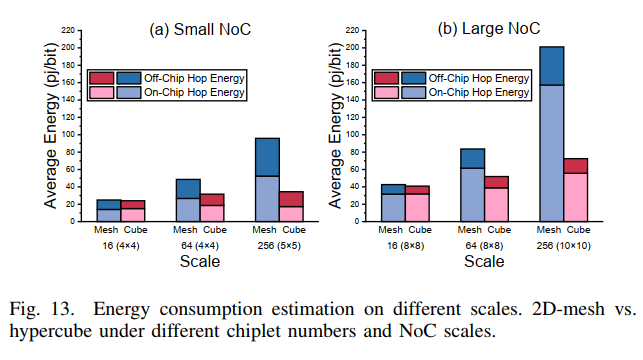
作者分析,正是因为采用了high-radix的设计,减少了intra-chiplet和inter-chiplet的hop counts,从而减小能耗。
- task4: C2Clink bandwidth
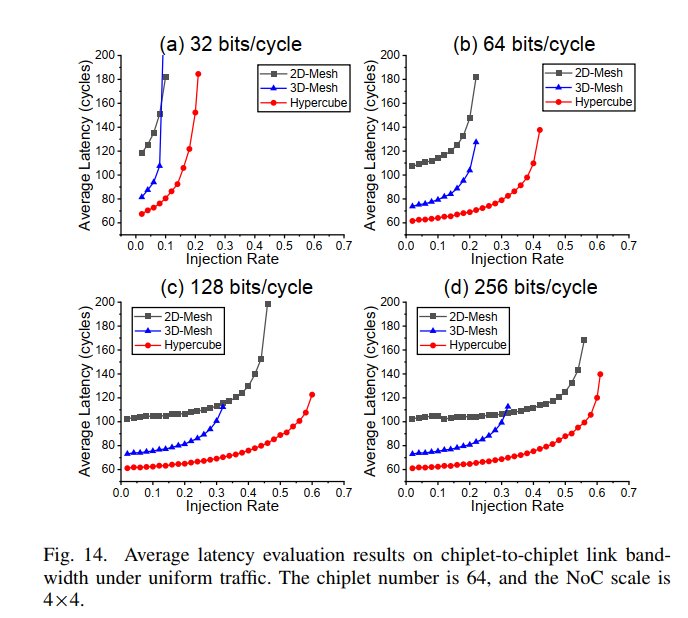
hypercube始终保持两倍的饱和注入率和一半的延迟。但是如果link的带宽太高,high-radix带来的优势会逐渐减少,因为此时的瓶颈变成了intra-chiplet link。
- task5: C2Clink latency & buffersize
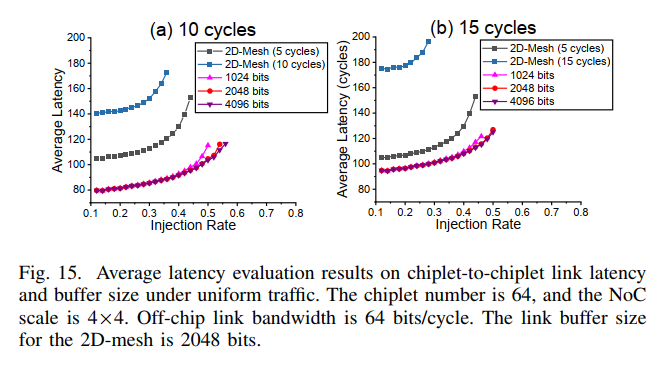
buffersize对性能影响很小。下面的红线代表hypercube-15cycles,仍然比2D-mesh-5cycles好。
- task6: interleaving
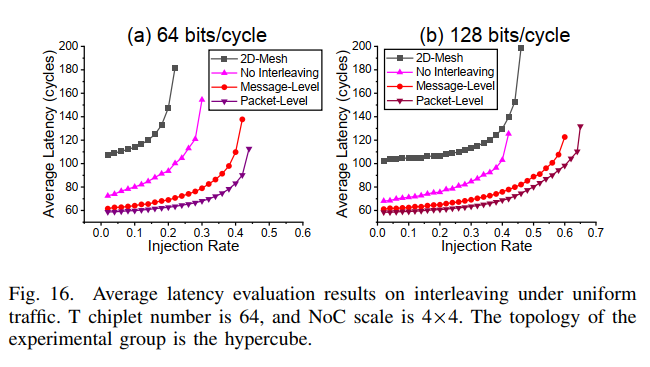
带宽越受限,效果越好(利用率成为瓶颈)。
Comment
读完文章,我对其性能提升并不意外,因为high-radix topo确实能带来好处,之前NoC不采用是因为实现问题。我还有一些疑问:
高bw时候性能反而不好,是否说明intra-chiplet routing algo不好?如果是,是否是为了支持high-radix设计(确实绕了远路)?能否避免?
- 是不是应该在2D-mesh上用本文的routing algo来比较一下效果,因为完全可以认为是hypercube和nD-mesh的优越性而不是路由算法好?
- 之前有无采用high-radix topo的文章?
- 之前的chiplet2chiplet设计是怎么办的?
- routing algo为什么不是很行?是因为在避免死锁吗?